

On Wednesday 27 September 2017
TUGAS DATA
MINING
MENGGUNAKAN
APLIKASI WEKA
Nama :
Muhammad Aulia Akhyar
NIM :
140500270
Assalammualaikum Warahmatullahi Wabarakatuh
Pada kesempatan kali ini saya akan menjelaskan sedikit
penggunaan aplikasi WEKA serta contoh dari pengklsifikasian dengan menggunakan
metode Naive Bayes, tutorial ini tercipta guna sebagai salah satu tugas kuliah
dari Mata Kuliah Data Mining, selamat membaca.
- Buka Aplikasi WEKA
Yang pertama dilakukan sudah pasti yaitu membuka aplikasi
WEKA yang nantinya akan kita gunakan dalam me-mining data, ketika aplikasi sedang proses membuka, maka akan
muncul seperti pada gambar dibawah ini.

- Buka Data yang Akan Diolah
Sebelum kita mengolah data yang akan kita olah nantinya,
terlebih dahulu kita harus membuka file yang akan kita olah, dengan mengklik
menu explorer. Setelah itu klik tab open file dan carilah data yang akan
kita gunakan, dalam kasus ini saya menggunakan data yang berjudul chronic kidney disease, silahkan melihat
gambar dibawah ini:
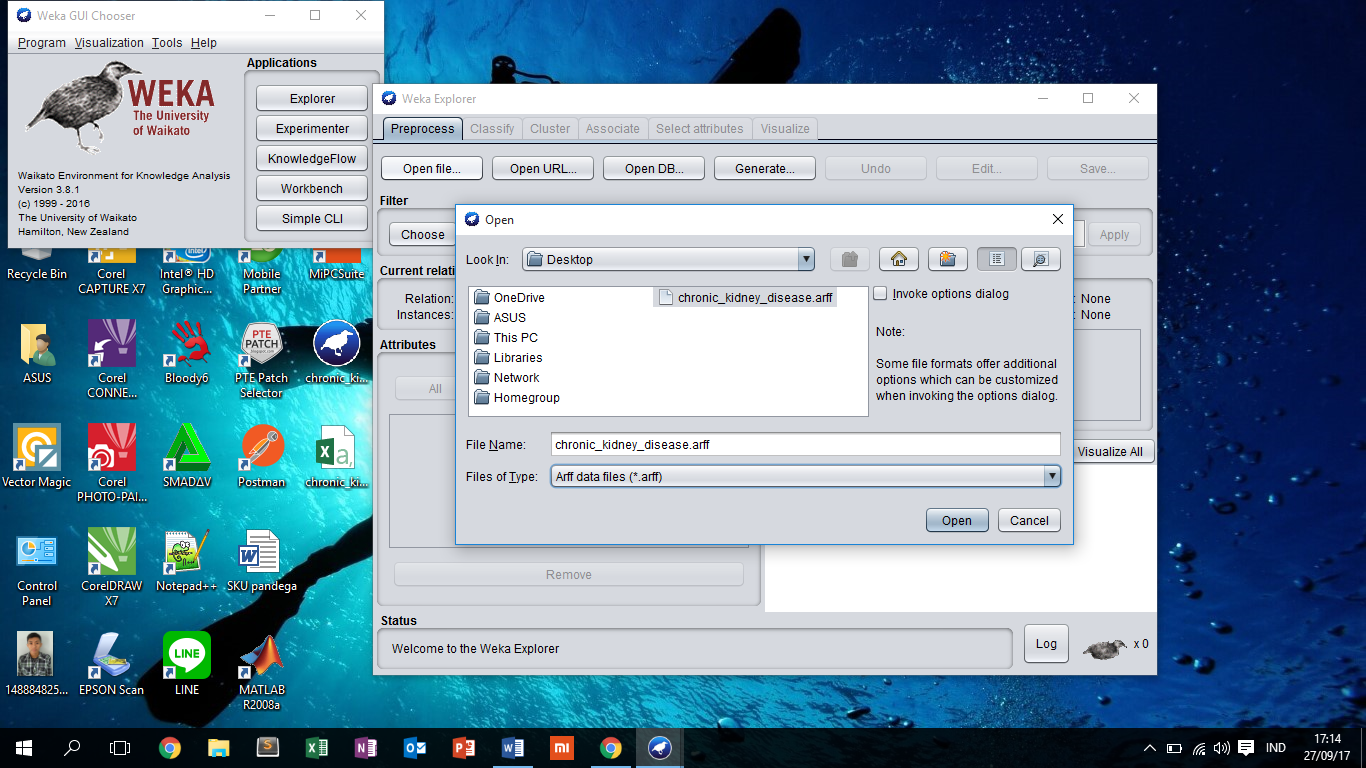
Lalu data
akan tampil pada WEKA seperti gambar yang ada dibawah ini:

- Menyimpan dengan format CSV
Setelah kita membuka
file data tadi, maka kita harus menyimpannya dengan format CSV, maka gantilah
format dengan mengklik pilihan files of types dari yang berformat arff, menjadi
CSV, seperti gambar yang ada dibawah ini:

Dan untuk pemformatan data menjadi CSV telah selesai,
selanjutnya kita akan membahas proses analisis data di WEKA dengan metode Naive
Bayes.
- Analisis Data dengan Metode Naive Bayes
Naive bayesian klasifikasi adalah suatu klasifikasi
berpeluang sederhana berdasarkan aplikasi teorema Bayes dengan asumsi antar
variabel penjelas saling bebas (independen). Dalam hal ini, diasumsikan bahwa
kehadiran atau ketiadaan dari suatu kejadian tertentu dari suatu kelompok tidak
berhubungan dengan kehadiran atau ketiadaan dari kejadian lainnya.
Naive Bayesian dapat digunakan untuk berbagai macam
keperluan antara lain untuk klasifikasi dokumen, deteksi spam atau filtering
spam, dan masalah klasifikasi lainnya. Dalm hal ini lebih disorot mengenai
penggunaan teorema Naive Bayesian untuk spam filtering
Teorema
Naive Bayesian memiliki beberapa kelebihan dan kekurangan yaitu sebagai berikut
:
Keuntungan Naive Bayesian :
- Menangani kuantitatif dan data diskrit
- Kokoh untuk titik noise yang diisolasi, misalkan titik yang dirata – ratakan ketika mengestimasi peluang bersyarat data.
- Hanya memerlukan sejumlah kecil data pelatihan untuk mengestimasi parameter (rata – rata dan variansi dari variabel) yang dibutuhkan untuk klasifikasi.
- Menangani nilai yang hilang dengan mengabaikan instansi selama perhitungan estimasi peluang
- Cepat dan efisiensi ruang
- Kokoh terhadap atribut yang tidak relevan
Kekurangan Naive Bayesian :
- Tidak berlaku jika probabilitas kondisionalnya adalah nol, apabila nol maka probabilitas prediksi akan bernilai nol juga
- Mengasumsikan variabel bebas
Untuk membuat data dengan Naive Bayes, maka ikuti langkah di bawah berikut ini.
Klik Open file, lalu
pilih file yang tadi kita gunakan, lalu klik filter dan pilih atribute
numerictonominal seperti gambar dibawah ini:
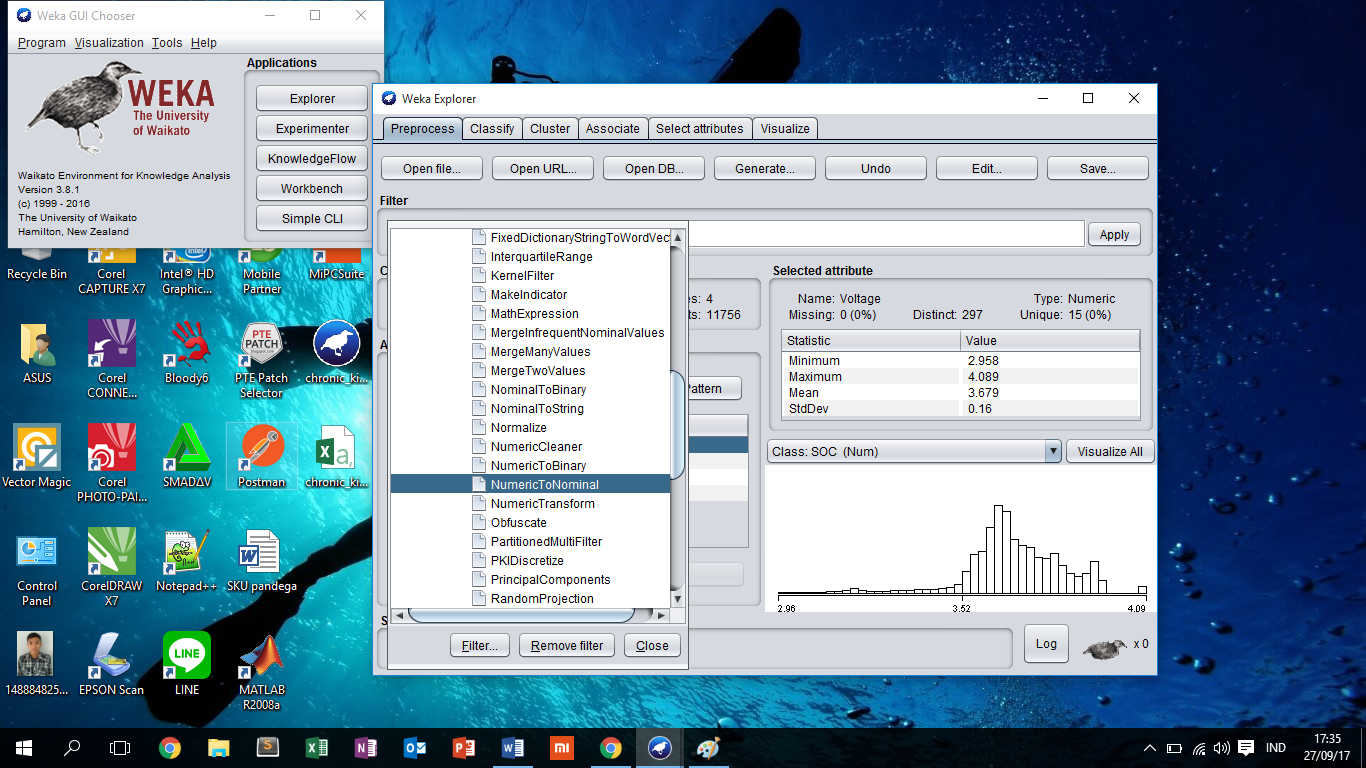
Selanjutnya
pindah pada tab classify, pada menu classifier yang tersedia, carilah
NaiveBayes sebagai model klasifikasi yang kita gunakan, setelah itu klik start
pada aplikasi, maka tampilan akhir untuk peng-klasifikasian menggunakan metode
NaiveBayes adalah seperti pada gambar di bawah ini.

Sekian dan Terimakasih atas
perhatian nya.
Sumassalammualaikum Warahmatullahi Wabarakatuh

Post a Comment