
On Friday, 29 September 2017
Nama : Muhammad Aulia Akhyar
NIM : 140500270
Contoh Ide Teks Mining
Contoh Ide Text Mining : "Analisis Sentimen pada Path"
Langkah-langkah Text Pre-processing pada "Analisis Sentimen Post pada path" :
Contoh : Misal terdapat input kalimat seperti :
Update status
gagal terus, giliran sms sampah,cepet masuk @telkomsel
http://t.co/Ul8fxv3xYz
gambar 1.1
Maka setelah melalui proses RemoveURLMentionHashtag maka Post tersebut berubah
menjadi seperti ini :
Update status
gagal terus, giliran sms sampah,cepet masuk

gambar 1.2
Maka setelah melalui proses ToLowerCase maka huruf besar dalam kalimat
tersebut berubah menjadi huruf kecil :
update status
gagal terus, giliran sms sampah,cepet masuk dasar.

gambar 1.3
Kemudian setelah proses penghilangan delimiter dan penguraian kalimat
maka hasilnya adalah sebagai berikut :


gambar 1.4
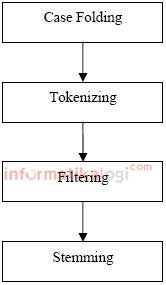
Tahapan Pre-Processing
Berdasarkan ketidak
teraturan struktur data teks, maka proses sistem temu kembali
informasi ataupun text mining memerlukan beberapa tahap awal
yang pada intinya adalah mempersiapkan agar teks dapat diubah menjadi lebih
terstruktur. Salah satu implementasi dari text mining adalah tahap Text Preprocessing.
Tahap Text Preprocessing adalah tahapan dimana aplikasi
melakukan seleksi data yang akan diproses pada setiap dokumen. Proses
preprocessing ini meliputi (1) case folding, (2) tokenizing, (3) filtering,
dan (4) stemming.
Tahap Preprocessing
1.
Case Folding
Tidak semua dokumen teks
konsisten dalam penggunaan huruf kapital. Oleh karena itu, peran Case Foldingdibutuhkan dalam mengkonversi keseluruhan
teks dalam dokumen menjadi suatu bentuk standar (biasanya huruf kecil atau
lowercase). Sebagai contoh, user yang ingin mendapatkan informasi “KOMPUTER” dan mengetik “KOMPOTER”, “KomPUter”, atau “komputer”, tetap
diberikan hasil retrieval yang sama yakni “komputer”. Case
folding adalah mengubah semua huruf dalam dokumen menjadi huruf kecil. Hanya
huruf ‘a’ sampai dengan ‘z’ yang diterima. Karakter selain huruf dihilangkan
dan dianggap delimiter.
2.
Tokenizing
Tahap Tokenizing adalah tahap pemotongan string input
berdasarkan tiap kata yang menyusunnya. Contoh dari tahap ini dapat dilihat
pada gambar dibawah ini.

Tahap Tokenizing
Tokenisasi secara garis besar memecah sekumpulan
karakter dalam suatu teks ke dalam satuan kata, bagaimana membedakan
karakter-karakter tertentu yang dapat diperlakukan sebagai pemisah kata atau
bukan.
Sebagai contoh karakter
whitespace, seperti enter, tabulasi, spasi dianggap sebagai pemisah kata. Namun
untuk karakter petik tunggal (‘), titik (.), semikolon (;), titk dua (:) atau lainnya, dapat memiliki peran yang cukup
banyak sebagai pemisah kata.
Dalam memperlakukan karakter-karakter dalam teks
sangat tergantung pada kontek aplikasi yang dikembangkan. Pekerjaan tokenisasi
ini akan semakin sulit jika juga harus memperhatikan struktur bahasa
(grammatikal).
3.
Filtering
Tahap Filtering adalah tahap mengambil kata-kata penting
dari hasil token. Bisa menggunakan algoritma stoplist (membuang
kata kurang penting) atau wordlist (menyimpan kata
penting). Stoplist/stopword adalah kata-kata yang tidak deskriptif
yang dapat dibuang dalam pendekatan bag-of-words. Contoh stopwords adalah “yang”, “dan”, “di”, “dari” dan
seterusnya. Data stopword dapat diambil dari jurnal Fadillah Z Tala
berjudul ”A Study of Stemming Effects on Information Retrieval in Bahasa
Indonesia”

Tahap Filtering
Kata-kata seperti “dari”, “yang”, “di”, dan “ke” adalah beberapa
contoh kata-kata yang berfrekuensi tinggi dan dapat ditemukan hampir dalam
setiap dokumen (disebut sebagai stopword). Penghilangan stopword ini dapat
mengurangi ukuran index dan waktu pemrosesan. Selain itu, juga dapat mengurangi
level noise.
Namun terkadang stopping
tidak selalu meningkatkan nilai retrieval. Pembangunan daftar stopword (disebut
stoplist) yang kurang hati-hati dapat memperburuk kinerja sistem Information Retrieval (IR). Belum ada suatu kesimpulan
pasti bahwa penggunaan stopping akan selalu meningkatkan nilai retrieval,
karena pada beberapa penelitian, hasil yang didapatkan cenderung bervariasi.
4.
Stemming
Pembuatan indeks
dilakukan karena suatu dokumen tidak dapat dikenali langsung oleh suatu Sistem Temu Kembali
Informasi atau Information Retrieval System
(IRS). Oleh karena itu, dokumen tersebut terlebih dahulu perlu
dipetakan ke dalam suatu representasi dengan menggunakan teks yang berada di dalamnya.
Teknik Stemming diperlukan selain untuk memperkecil
jumlah indeks yang berbeda dari suatu dokumen, juga untuk melakukan
pengelompokan kata-kata lain yang memiliki kata dasar dan arti yang serupa
namun memiliki bentuk atau form yang berbeda karena mendapatkan imbuhan yang
berbeda.
Sebagai contoh kata
bersama, kebersamaan, menyamai, akan distem ke root word-nya yaitu “sama”. Namun, seperti halnya stopping, kinerja
stemming juga bervariasi dan sering tergantung pada domain bahasa yang
digunakan.
Proses stemming pada teks berbahasa Indonesia
berbeda dengan stemming pada teks berbahasa Inggris. Pada teks berbahasa
Inggris, proses yang diperlukan hanya proses menghilangkan sufiks. Sedangkan
pada teks berbahasa Indonesia semua kata imbuhan baik itu sufiks dan prefiks
juga dihilangkan.

Tahap Stemming

{kind=link}
Post a Comment